Moin Leute,
ich möchte Dateien inhaltlich vergleichen, um so vllt eine nur 90%ige Übereinstimmung zu ermitteln. Hierfür schiebe ich die jeweiligen Byteblöcke einer Datei über andere Ähnliche Dateien. Bei den Tests mit simplen kurzen .txt-Dateien klappt das wunderbar. Wenn ich jetzt aber eine .pdf-Datei mit einer .docx-Datei vergleiche, die vom Text und Format identisch sind, denn erhalte ich nicht mal eine 1%ige Übereinstimmung.
Das Speichern der Byteblöcke habe ich wie folgt geregelt:
[highlight=c#]
byte[] pufferNextFile = new byte[byteStep];
using (BinaryReader breaderCurrentFile = new BinaryReader(new FileStream(nextFile.FullName, FileMode.Open)))
{
breaderCurrentFile.BaseStream.Seek(positionNextFil e, SeekOrigin.Begin);
breaderCurrentFile.Read(pufferNextFile, 0, pufferNextFile.Length);
}
[/highlight]
Wenn ich mir den Text-Inhalt beider Dateien nun mit Hilfe von ASCIIEncoding().GetString(pufferNextFile) anschaue, denn wird auch nirgendwo ein leserlicher string erkenntlich. Woran kann das liegen? Werden die bytes aufgrund der unterschiedlichen Dateitypen wirklich komplett anders hinterlegt? Denn müsste ich mir ja wahrscheinlich für jedes Dokument eine weitere Bibliothek zulegen (wie zB https://www.codeproject.com/Articles...m-PDF-in-C-NET). Oder habe ich falsch entwickelt?
Der Algorithmus ist ziemlich komplex, deswegen lasse ich ihn erst mal außen vor. Falls er für die Frage doch noch relevant sein sollte, füge ich ihn mit samt der anderen Klassen hinzu.
VG
-
Vor Version 2.0 (d.h. Juli 1996) waren es noch 65.536 Codepunkte.
Windows 2000 war das erste Windows welches Unicode unterstützte, das kam Februar 2000 raus - also vier Jahre später.
Oracle fing im Release 8i (1997) mit Unicode an. Beim Linux "GNU C Library" war es Release 2.2 (2000)
Ich denke du wirst recht lange suchen müssen bis du eine Software findest welche bereits Unicode Version < 2.0 unterstützt hat. -
Hmm. Das hat sich mit der Zeit geändert, und ich habe das glücklicherweise nicht mitbekommen:
"Originally, Unicode was designed as a pure 16-bit encoding,.." http://unicode.org/faq/utf_bom.html
Danke. Für die Hinweise.
Rant:
Da baut man einen Standard um mal hart alte Zöpfe abzuschneiden, aber dann kreiert man eigenen Schwachsinn (ja, meine Meinung), indem wieder Spezialcharakter und Bereiche nur für die Codierung definiert...
Da muss man wieder Spezialfälle im Kopf haben, und Sonderbehandlungen im Code machen. Da muss ich mir nochmal den C++ Code ansehen - das hatte hier noch keiner auf dem Radar... :-(Leave a comment:
-
utf-16 heißt nicht das die Zeichen mit 16bit kodiert sind. Das solltest du auch nachlesen.Leave a comment:
-
Danke für die Korrekturen, stimmt.
Aber das mit dem Unicode muss ich nochmal nachlesen.. (z.B. UTF-16 -> 2^16 = 65K Unterschiedliche Zeichen)Leave a comment:
-
Ein paar kleine Korrekturen, da du so höflich darum gebeten hast:
Die Amerikanische Codepage für OEM (das "DOS" Fenster) ist CP437, nicht CP470. CP850 für West-Europa stimmt hingegen.
Die Windows Codepage für West-Europäsche Sprachen ist CP1252. CP1250 wird für Ost-Europäische Sprachen verwendet.
Unicode hatte am Anfang (bis Version 2.0) tatsächlich nur 65.536 Zeichen vorgesehen, heute sind es theoretisch 1.114.112 Zeichen, genauer gesagt Codepunkte.
UTF-8, UTF-16 und UTF-32 ist nur die Methode wie man diese Codepunkte codiert. Jeder dieser Methoden (UTF-8, UTF-16 und UTF-32) kann alle Unicode Codepunkte codieren, bzw. darstellen.
GrussLeave a comment:
-
Wozu die Byteschieberei?
Für Textdateien ist es sinnvoller die Stringverarbeitung zu nutzen.
Du wirst nicht darum herum kommen je Dateityp eine eigene Vergleichsklasse anzuwenden.
Insofern ist ein erster Schritt bei Textdateien diese bis zu einer Größe in einen String einzulesen, diesen von unerwünschten Zeichen zu befreien (Whitespaces, Zeilenumbrüche, Zeichensetzung).
Den so erhaltenen Text (bsp. "HalloWeltdadraussen") kann man dann vergleichen. Ab einer Größe kann man Blockweise arbeiten.
Damit findet man allerdings dann nur Texte, die identisch sind, aber unterschiedlich formatiert.
Weitere Möglichkeit ist, alle Worte in eine HashMap zu lesen und diese dabei zu zählen. Hat man nun in beiden Texten ungefähr die gleichen Worte in der ungefähr gleichen Anzahl könnte ein hoher Grad der Übereinstimmung erreicht sein.
Das sind nur Methoden für Textdateien; für Binärdateien ist das unbrauchbar.
Und wie Ralf schon sagte: Warum keine Versionsverwaltung?Leave a comment:
-
Klingt eher danach das man eine sauber Dokumenten- und/oder Versions-Verwaltung bräuchte. Das wäre aber gleich ein ganz anderes Thema und hilft bei den Fehlern der Vergangenheit nicht.
Wenn du auch Dokumenttyp übergreifend oder auch nur andere Formate als Plaintext vergleichen willst willst wird dich ein Vergleich auf Byte Ebene nicht weiterbringen. Die meisten Formate können sich bei einer auch nur minimalen Änderungen auf binär komplett anders darstellen. Kleine Änderungen in der Datei korrelieren oft genug nur wenig mit kleinen Änderungen im Speicherformat der Datei. Wenn du insbesondere textuelle Formate vergleichen willst, also keine Medienformate oder sowas, dann würde ich empfehlen die Dateien vorzubearbeiten und in ein vergleichbares Format zu bringen. Zum Beispiel den Weg den die klassischen Volltextindexierer nehmen bieten sich hier an. Weg wäre also den Plaintext zu extrahieren so das man ein simpel vergleichbares irgendwas bekommt. Beim extrahieren hilft zum Beispiel die IFilter Schnittstelle in Windows. Für die üblichen verdächtigen Dateitypen im Businessbereich sollte man immer einen passenden IFilter finden, also ein Ding das den Plaintext aus der Datei extrahiert, und diesen sollte man einigermaßen dann untereinander vergleichen können.Leave a comment:
-
Danke für deine Rückmeldung, Ralf Jansen.
Ziel soll es letztendlich sein, dass die Software dem Mitarbeiter "inhaltsähnliche" Dokumente anzeigt. Die Dokumente müssen hierbei nicht zu 100% übereinstimmen. Wenn der Mitarbeiter also sieht, dass von der "gleichen" Excel-Arbeitsmappe (oder einem .docx, oder einem .txt, ....-Dokument) drei verschiedene Versionen vorliegen, so kann er diese bis auf die aktuellste Version entfernen. Das soll vorbeugen, dass die Mitarbeiter in verschiedene Versionen schreiben und man den Überblick verliert. Die Organisation des Arbeitsumfeldes soll also verbessert werden, um so am letzten Ende auch Kosten zu sparen. Welcher Bereich als ähnlich einzustufen ist, habe ich noch nicht direkt festgelegt: ob nun 15% oder 75% Gleichheit eine Ähnlichkeit ausmachen - das müsste ich halt erst nach dem Testen bestimmen (oder weiterhin variabel halten). Zu mal hier ja auch das Problem besteht, dass Dateiinhalte selbst mit Trennung ähnlich sein können: bspws. ist "Hallo Welt" auch inhaltsähnlich mit "Hallo schöne Welt". Das Problem würden meine bisherigen Algorithmen noch nicht lösen. Aber bis dahin komme ich ja auch noch gar nicht, wenn 600KB über zwei Minuten zum Einlesen benötigen..
MfGLeave a comment:
-
Ohne dein Verfahren genau analysiert zu haben kannst du vermutlich nur durch passende Wahl der Blockblöcke alles als ähnlich oder nicht ähnlich definieren das sieht doch mehr nach Voodoo aus als nach einem brauchbaren Verfahren um Ähnlichkeit festzustellen.
Auch wenn hier schon jemand seinen Unmut über Motivationsfragen geäußert hat stelle ich so'ne Frage trotzdem, ohne konkreter Zieldefinition sehe ich keine vernünftige Hilfemöglichkeit. Was ist das Ziel dieses Verfahren? Wie definierst du ähnlich. In welchem Kontext soll diese Art der Ähnlichkeit helfen?Leave a comment:
-
Hallo Leute,
vielen Dank für eure vielen tollen Anregungen! Es tut mir auch leid, dass es hier nun zu Missverständnissen kam!
Ich muss Christian Marquardt an dieser Stelle leider Recht geben. Mein Ziel ist es primär nicht gewesen, unterschiedliche Codierungen miteinander zu vergleichen. Das war wohl ein blöder Ausrutscher von mir, das hätte ich wissen müssen.. Trotzdem ist der Exkurs von Ralph Erdt sehr interessant gewesen. Spannend fande ich vor allem auch dass Windows die Dateien mit samt ihren Metadaten archiviert vorlegt. Aber das ist wohl nun auch ein anderes Thema..
Ich bin mittlerweile immer noch dabei Dateien (diesmal mit gleicher Codierung) miteinander zu vergleichen. Bei sehr kleinen Textdateien verläuft alles reibungslos, aber sobald es an die 2000Bytes ran geht, tauchen schon die Probleme auf.
Mein erster Feldversuch war es, 10% der Datei als Byteblock zu nehmen und diesen byteweise über eine zweite Datei zu schieben. Sollte keine Gleichheit vorhanden sein, so wird der Byteblock aus Datei 1 ein Byte weiter gesetzt und wieder über Datei 2 geschoben:
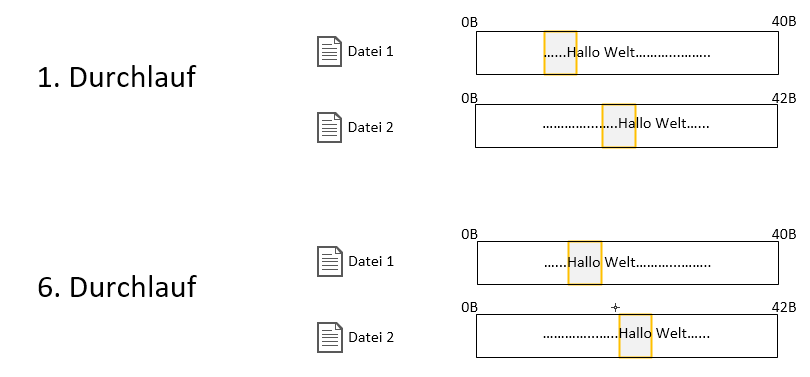
http://fs5.directupload.net/images/161225/keruq7vj.png
Im worst case bei einer 2000Byte-Datei (und Byteblöcken von 25%) dauert das über 2 Minuten.. Klar, es wird ja auch über zwei Millionen mal verglichen:
(Dateigröße – Byteblockgröße * Dateigröße – Byteblockgröße) = (2000 – 500) * (2000 - 500) = ~2,3 Mio.
Für nur 1,95KB könnt ihr euch mein Entsetzen sicher vorstellen. Darum habe ich mir eine andere Strategie ausgedacht: ich zerstückel die erste Datei wieder byteweise in Byteblöcke, packe diese nun aber verschlüsselt in eine MD5-Liste. Jetzt durchlaufe ich die zweite Datei byteweise und schaue, ob der Byteblock der zweiten Datei in MD5-verschlüsselter Form in der MD5-Liste der ersten Datei liegt. Bei 2000Bytes geht das nun innerhalb einer halben Sekunde. Juhu! Habe ich mich gefreut! Doch wenn ich nun statt der zuvorrigen 1,95KB-Datei die Größe erhöhe auf 600KB, dann dauert allein das Einlesen und Verschlüsseln der Datei über 2 Minuten:
[highlight=c#]
FileInfo currentFile = new FileInfo(@"C:/test.txt");
int positionCurrentFile = 0;
int byteStep = (int)((currentFile.Length * 25) / 100); //25% der aktuellen Dateilänge
MD5 md5 = new MD5CryptoServiceProvider();
List<byte[]> md5s = new List<byte[]>();
//So lange Byte in aktueller Datei vorhanden
while (((positionCurrentFile + byteStep) < currentFile.Length))
{
byte[] pufferCurrentFile = new byte[byteStep];
//Byteblock aus aktueller Datei in byteArray "pufferCurrentFile" zwischenspeichern
using (BinaryReader breaderCurrentFile = new BinaryReader(new FileStream(currentFile.FullName, FileMode.Open)))
{
breaderCurrentFile.BaseStream.Seek(positionCurrent File, SeekOrigin.Begin);
breaderCurrentFile.Read(pufferCurrentFile, 0, pufferCurrentFile.Length);
}
//Bytearray als md5 in Liste speichern
md5s.Add(md5.ComputeHash(pufferCurrentFile));
positionCurrentFile++;
}
[/highlight]
Einerseits verständlich. Ich führe für 600KB wieder 614.400 Operationen(Bytepositionierung, Zwischenspeichern, Verschlüsseln) durch... Mein Ansatz wäre nun, die Byteblöcke nicht byteweise zu verschieben, sondern die Schrittweise auf Basis der Dateigröße anzupassen. Das heißt, ich springe nicht 1 Byte weiter und erzeuge den Block, sondern vielleicht jeweils immer 10KB in der 600KB-Datei. Dann hätte ich mit 60 Operationen zwar eine imens kürzere Rechenzeit, würde das Ergebnis jedoch verfälschen, da mit hoher Wahrscheinlichkeit keine Gleichheit heraus käme.
Ein anderer Ansatz wäre vielleicht das Multithreading. Ich könnte die Byteblöcke ja vielleicht von vorne wie von hinten abspeichern, und sobald sich die beiden Threads kreuzen, beende ich das Verfahren. Wobei ich dies an der Stelle für etwas zu "doll" geeignet finde. Ich bin mit dem Thema noch nicht so vertraut und befürchte ein schwereres Handling von Deadlocks. Bei zwei Threads statt einem wäre die Rechenzeit dann auch "nur" doppelt so schnell und wieder problematisch bei größeren Dateien.
Nun gut... Ich hoffe, das war nicht zu viel für euch.
Habt ihr einen Rat wie ich die Analyse beschleunigen könnte? Gibt es noch einen besseren Schritt Richtung MD5's? Oder muss ich Multithreading einsetzen? Geht es sonst vielleicht noch irgendwo anders lang?
Für Hinweise wäre ich echt dankbar..
MfGZuletzt editiert von kogen; 25.12.2016, 22:53.Leave a comment:
-
Nein, das ist kein untergeordnetes Problem. Im Gegenteil es kommt noch vor dem Codierungsproblem. Was nützt mir das ev. gelöste Codierungsroblem, wenn ich den Aufbau der Binärdatei nicht verstehe.Originally posted by Ralph Erdt (2) View Post
Tja, wenn man natürlich nicht diskutieren will, ob es nicht bessere oder einfachere Werkzeuge oder Frameworks gibt...dann mal los. Da geht es nach dem Motto "Warum einfach, wenn es auch kompliziert geht"
Hmm, warum gibt es wohl entsprechende Objekte unter MS um auf Word Excel usw. zugreifen zu können?
Warum gibt es Libs. die einem aus einem PDF-Dokumenet den reinen Text liefern?
Was könnte man dann vergleichen?
Es gibt sinnvolle Vorgehenweisen und auch weniger sinnvolle Vorgehensweisen. Und bei letzterem dürfte doch wohl die Frage erlaubt sein, warum so vorgegangen wird.Zuletzt editiert von Christian Marquardt; 23.12.2016, 17:19.Leave a comment:
-
Wegen Binärformat hatte ich ja vorher was geschrieben. Und selbst wenn es unterschiedliche Codierungen sind (was mit guten Libs eigentlich einstellbar ist) - so ist das IMHO erstmal ein untergeordnetes Problem. Erstmal muss man an den Plain-Text kommen. Wenn das geschafft ist, dann sollte man schon was machen können (zumal er ja nur einen Fuzzy Vergleich machen will, bei dem die Sonderzeichen nur wenige Prozent ausmachen sollten).Originally posted by Christian Marquardt View Post
Sorry, aber ich HASSE Motivationsfragen! Sicherlich kann man über andere Wege diskutieren wenn man die Motivation wüsste, aber er hat sich sicherlich überlegt, warum er es so machen will - auch wenn die Antwort nur "lernen" heißt. Er hat mit seiner Frage IMHO Verständnisprobleme in der konkreten technischen Umsetzung (wie andere das machen) gezeigt, und daher kann man meines Erachtens ruhig mal etwas den Erklärbär machen (ich hoffe, ich habe das brauchbar gemacht?). In meinen Anfangszeiten hatte ich auch häufig so hilfreiche Antworten wie "Wieso willst Du das machen?" anstatt "Das geht so nicht, versuch mal den Weg X.". Die Diskussionen waren unsinnig und nur bremsend. Aus diesem Grund handel ich so.Originally posted by Christian Marquardt View PostLeave a comment:
-
??Was bleibt für Dich (den OP) zu beachten: Erstmal nichts.Mach einfach weiter wie gehabt.
Das sicherlich nicht. Das Vorgehen Inhalte von Binärformaten per ASCII vergleichen zu wollen ist.....wenig sinnvoll. Zumal zu der Zeichsatzproblematik die Problematik des Formates kommt.
Des Weiteren wäre es interessant zu wissen, warum nun ein *.doc mit einem *.pdf verglichen werden muss. Warum hat da offenbar jemand (oder mehrere?) einmal ein Worddokument und ein identisches PDF-Dokument zu Fuß erzeugt ohne eines von andern erzeugen zu lassen (PDF-Druck).Leave a comment:
Leave a comment: