 Tweet
Tweet
Hallo zusammen,
ich bin neu sowohl hier im Forum wie auch im Beruf des Anwendungsentwicklers.
Jetzt habe ich gleich zu Beginn meiner Ausbildung die Chance bekommen, ein interessantes Projekt umzusetzen.
Dabei geht es um die Überprüfung einer Replikation von diversen Tabellen.
Im Zuge dieses Projektes habe ich mir jetzt ein wenig PL/SQL beigebracht und mein Script ermittelt auch die entprechenden Tabellen um sie zu überprüfen.
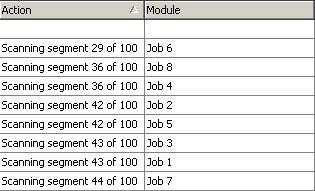
Ein großes Problem waren dann die größeren Tabellen, welche bis zu 20 Gigabyte groß sind. Dafür habe ich eine Prozedur entwickelt, die zuerst anhand diverser Kriterien einzelne Segmente ermittelt, in die diese größeren Tabellen sozusagen zerlegt werden können.
Dann werden zugunsten der Geschwindigkeit mehere Jobs leicht versetzt, aber sich überschneidend gestartet, welche die einzelnen Segmente jeweils parallel überprüfen.
Mein Problem ist nun, dass sich diese einzelnen Jobs gegenseitig keine Daten zuschicken können, und ich auch keine globalen Variablen benutzen kann/darf/soll. Also lasse ich einfach eine temporäre Tabelle erzeugen, welche immer nur eine Zeile enthält, in der jeweils die entsprechenden Daten stehen, wie z.B. welches Segent als nächstes geprüft werden muss. Die einzelnen Jobs nehmen sich beim Start dann diesen Wert und setzen ihn im Anschluss sofort höher, damit der nächste Job dann nicht das selbe Segment scannt.
Das Problem ist jetzt nur, dass sich die Jobs gegenseitig zu locken scheinen. Jedenfalls sehe ich nach kurzer Zeit immer, dass die Jobs alle mit einem Lock versehen sind und auch gleichzeitig versuchen die temporäre Tabelle zu "updaten" (mir fällt doch tatsächlich kein vernünftiger Begriff dafür ein).
Ich habe auch google bemüht, aber entweder mein Problem ist hier ein ganz besonderes, oder aber ich suche nach den falschen Wörtern.
Es wäre wirklich klasse wenn mir jemand dazu einen Tipp geben könnte, in der Firma ist gerade sowohl Urlaubsphase, als auch einiger Stress wegen diversen anderen Problemen, so dass ich momentan einfach nicht die Möglichkeit habe jemand von den Kollegen zu fragen.
ich bin neu sowohl hier im Forum wie auch im Beruf des Anwendungsentwicklers.
Jetzt habe ich gleich zu Beginn meiner Ausbildung die Chance bekommen, ein interessantes Projekt umzusetzen.
Dabei geht es um die Überprüfung einer Replikation von diversen Tabellen.
Im Zuge dieses Projektes habe ich mir jetzt ein wenig PL/SQL beigebracht und mein Script ermittelt auch die entprechenden Tabellen um sie zu überprüfen.
Ein großes Problem waren dann die größeren Tabellen, welche bis zu 20 Gigabyte groß sind. Dafür habe ich eine Prozedur entwickelt, die zuerst anhand diverser Kriterien einzelne Segmente ermittelt, in die diese größeren Tabellen sozusagen zerlegt werden können.
Dann werden zugunsten der Geschwindigkeit mehere Jobs leicht versetzt, aber sich überschneidend gestartet, welche die einzelnen Segmente jeweils parallel überprüfen.
Mein Problem ist nun, dass sich diese einzelnen Jobs gegenseitig keine Daten zuschicken können, und ich auch keine globalen Variablen benutzen kann/darf/soll. Also lasse ich einfach eine temporäre Tabelle erzeugen, welche immer nur eine Zeile enthält, in der jeweils die entsprechenden Daten stehen, wie z.B. welches Segent als nächstes geprüft werden muss. Die einzelnen Jobs nehmen sich beim Start dann diesen Wert und setzen ihn im Anschluss sofort höher, damit der nächste Job dann nicht das selbe Segment scannt.
Das Problem ist jetzt nur, dass sich die Jobs gegenseitig zu locken scheinen. Jedenfalls sehe ich nach kurzer Zeit immer, dass die Jobs alle mit einem Lock versehen sind und auch gleichzeitig versuchen die temporäre Tabelle zu "updaten" (mir fällt doch tatsächlich kein vernünftiger Begriff dafür ein).
Ich habe auch google bemüht, aber entweder mein Problem ist hier ein ganz besonderes, oder aber ich suche nach den falschen Wörtern.
Es wäre wirklich klasse wenn mir jemand dazu einen Tipp geben könnte, in der Firma ist gerade sowohl Urlaubsphase, als auch einiger Stress wegen diversen anderen Problemen, so dass ich momentan einfach nicht die Möglichkeit habe jemand von den Kollegen zu fragen.


Comment