 Tweet
Tweet
Moin Leute,
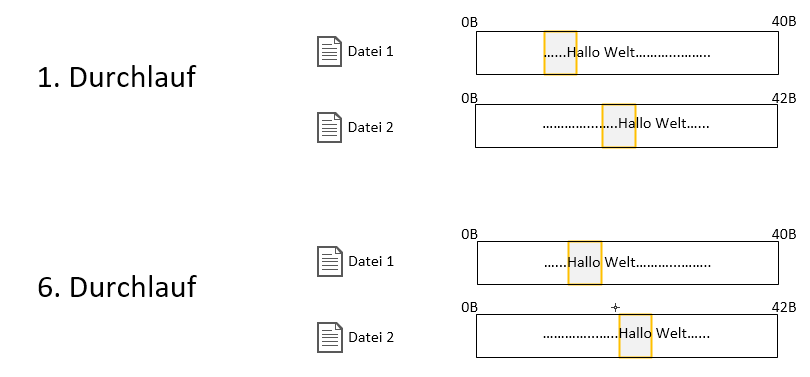
ich möchte Dateien inhaltlich vergleichen, um so vllt eine nur 90%ige Übereinstimmung zu ermitteln. Hierfür schiebe ich die jeweiligen Byteblöcke einer Datei über andere Ähnliche Dateien. Bei den Tests mit simplen kurzen .txt-Dateien klappt das wunderbar. Wenn ich jetzt aber eine .pdf-Datei mit einer .docx-Datei vergleiche, die vom Text und Format identisch sind, denn erhalte ich nicht mal eine 1%ige Übereinstimmung.
Das Speichern der Byteblöcke habe ich wie folgt geregelt:
[highlight=c#]
byte[] pufferNextFile = new byte[byteStep];
using (BinaryReader breaderCurrentFile = new BinaryReader(new FileStream(nextFile.FullName, FileMode.Open)))
{
breaderCurrentFile.BaseStream.Seek(positionNextFil e, SeekOrigin.Begin);
breaderCurrentFile.Read(pufferNextFile, 0, pufferNextFile.Length);
}
[/highlight]
Wenn ich mir den Text-Inhalt beider Dateien nun mit Hilfe von ASCIIEncoding().GetString(pufferNextFile) anschaue, denn wird auch nirgendwo ein leserlicher string erkenntlich. Woran kann das liegen? Werden die bytes aufgrund der unterschiedlichen Dateitypen wirklich komplett anders hinterlegt? Denn müsste ich mir ja wahrscheinlich für jedes Dokument eine weitere Bibliothek zulegen (wie zB https://www.codeproject.com/Articles...m-PDF-in-C-NET). Oder habe ich falsch entwickelt?
Der Algorithmus ist ziemlich komplex, deswegen lasse ich ihn erst mal außen vor. Falls er für die Frage doch noch relevant sein sollte, füge ich ihn mit samt der anderen Klassen hinzu.
VG
ich möchte Dateien inhaltlich vergleichen, um so vllt eine nur 90%ige Übereinstimmung zu ermitteln. Hierfür schiebe ich die jeweiligen Byteblöcke einer Datei über andere Ähnliche Dateien. Bei den Tests mit simplen kurzen .txt-Dateien klappt das wunderbar. Wenn ich jetzt aber eine .pdf-Datei mit einer .docx-Datei vergleiche, die vom Text und Format identisch sind, denn erhalte ich nicht mal eine 1%ige Übereinstimmung.
Das Speichern der Byteblöcke habe ich wie folgt geregelt:
[highlight=c#]
byte[] pufferNextFile = new byte[byteStep];
using (BinaryReader breaderCurrentFile = new BinaryReader(new FileStream(nextFile.FullName, FileMode.Open)))
{
breaderCurrentFile.BaseStream.Seek(positionNextFil e, SeekOrigin.Begin);
breaderCurrentFile.Read(pufferNextFile, 0, pufferNextFile.Length);
}
[/highlight]
Wenn ich mir den Text-Inhalt beider Dateien nun mit Hilfe von ASCIIEncoding().GetString(pufferNextFile) anschaue, denn wird auch nirgendwo ein leserlicher string erkenntlich. Woran kann das liegen? Werden die bytes aufgrund der unterschiedlichen Dateitypen wirklich komplett anders hinterlegt? Denn müsste ich mir ja wahrscheinlich für jedes Dokument eine weitere Bibliothek zulegen (wie zB https://www.codeproject.com/Articles...m-PDF-in-C-NET). Oder habe ich falsch entwickelt?
Der Algorithmus ist ziemlich komplex, deswegen lasse ich ihn erst mal außen vor. Falls er für die Frage doch noch relevant sein sollte, füge ich ihn mit samt der anderen Klassen hinzu.
VG
Comment